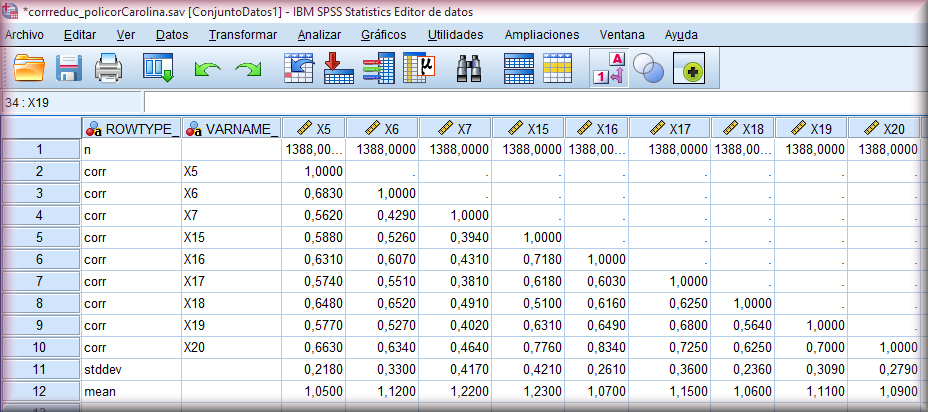
Si se desea introducir como datos de partida en AMOS una matriz de correlaciones, deberemos tener en cuenta que el archivo SPSS de datos debe tener la siguiente estructura:
-La primera variable, tipo cadena con nombre ROWTYPE_ (anchura 8 caracteres) deberá contener como información n, corr sttdev y mean.
-La segunda VARNAME_ (ancho 8) que contendrá los nombres de las variables en cada fila correspondiente.
-A continuación se encuentran las columnas con las variables analizadas.
Un ejemplo podría ser el siguiente caso (matriz policórica generada por el programa Factor (Ferrando y Lorenzo-Seva, 2017 ) y exportada al SPSS):